矩阵的特征分解(三步分解,带您了解特征工程)

入门特征工程:定义、步骤及案例
本文摘自《特征工程入门与实践》一书,作者是Sinan Ozdemir[土]和Divya Susarla[土],从零入手,帮你全面了解特征工程,提升机器学习算法的效率和准确率。
进阶推荐《精通特征工程》,作者是Alice Zheng[美]和Amanda Casari[美],通过Python示例掌握特征工程基本原则和实际应用,增强机器学习算法效果。
以下回答将从定义、步骤和案例三个部分解读特征工程。废话不多说,快上车!
一、特征工程的定义
特征工程(feature engineering)是指从原始数据中提取特征并将其转换为适合机器学习模型的格式。
为了提取知识和做出预测,机器学习使用数学模型来拟合数据。这些模型将特征作为输入。
特征就是原始数据某个方面的数值表示。在机器学习流程中,特征是数据和模型之间的纽带。
特征工程是数据科学和机器学习流水线上的重要一环,因为正确的特征可以减轻构建模型的难度,从而使机器学习流程输出更高质量的结果。
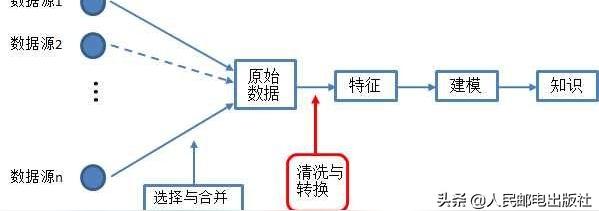
特征工程在机器学习流程中的位置
二、特征工程的5个步骤
经典特征工程包括探索性数据分析、特征理解、特征增强、特征构建和特征选择5个步骤,为进一步解释数据并进行预测性分析做准备。
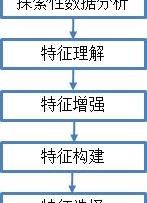
经典特征工程流程
1. 探索性数据分析
探索性数据分析(EDA,exploratory data analysis)
在应用机器学习流水线,甚至在使用机器学习算法或特征工程工具之前,我们应该对数据集进行一些基本的描述性统计(大小、形状),并进行可视化操作,以便更好地理解数据的性质。
2. 特征理解——识别数据
是指在数据集中识别并提取不同等级的数据,并用这些信息创造有用、有意义的可视化图表,帮助我们进一步理解数据。
当拿到一个新的数据集时,基本工作流程如下:
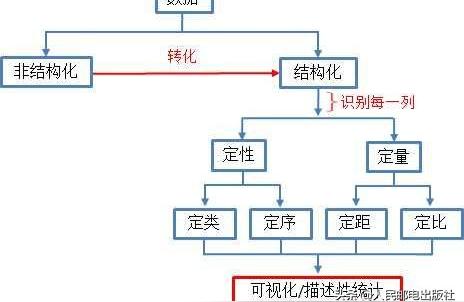
识别数据基本工作流程
a. 数据是结构化 OR 非结构化?
结构化(有组织)数据:可以分成观察值和特征的数据,一般以表格的形式组织(行是观察值,列是特征)。例如科学仪器报告的气象数据是高度结构化的,因为存在表格的行列结构。
非结构化(无组织)数据:作为自由流动的实体,不遵循标准组织结构(例如表格)的数据。通常,非结构化数据在我们看来是一团数据,或只有一个特征(列)。例如以原始文本格式存储的数据,服务器日志和推文等,是非结构化数据。
b. 数据是定量的 OR 定性的
一般情况下,在处理结构化的表格数据时,第一个问题是:数据是定量的,还是定性的?
定量数据本质上是数值,是衡量某样东西的数量。
定性数据本质上是类别,是描述某样东西的性质。
c. 每列数据处于哪个等级?
数据可分为定类、定序、定距和定比四个等级,每个等级都有不同的控制和数学操作等级。数据等级决定了可以执行的可视化类型和操作。
定类等级(nominal level):处理定性数据,只按名称分类,如血型、动物物种和人名。这个等级不能执行任何诸如加法、除法之类的数学操作,但是可以计数,因此可绘制条形图和饼图。
定序等级(nominal level):处理定性数据,这个等级的数据可以自然排序,可进行计数,也可引入比较。但是数据属性仍然属于类别。因为能够计算中位数和百分位数,所以可在条形图和饼图的基础上增加茎叶图和箱线图。
定距等级(nominal level):处理定量数据,可以对数值进行排序、比较和加减,引入算数平均数和标准差。可用散点图、直方图和折线图表示。
定比等级(nominal level):处理定量数据,存在有意义的绝对零点,可以对数值进行加减乘除运算,例如¥100是¥50的2倍。可用直方图和箱线图表示。
d. 对不同的数据等级进行不同的可视化表示。
3. 特征增强——清洗数据
这个阶段是关于改变数据值和列的,根据数据的等级填充缺失值,并按需执行虚拟变量转换和缩放操作。
清洗数据是指调整已有的列和行,增强数据是指在数据集中删除和添加新的列。
特征增强的意义是,识别有问题的区域,并确定哪种修复方法最有效。
识别数据中的缺失值
分析数据并了解缺失的数据是什么,这样才可以决定下一步如何处理这些缺失值。
首先进行探索性数据分析来识别缺失的值。可以使用Pandas和NumPy这两个Python包来存储数据并进行一些简单的计算,使用流行的可视化工具观察数据的分布情况。
处理数据集中的缺失值
处理缺失值最主要的两个方法是:
- 删除缺少值的行:通过这种操作会留下具有数据的完整数据点。
- 填充缺失值:填充指的是利用现有知识/数据来确定缺失的数量值并填充的行为。
对于数值数据,最常见的是用此列其余部分的均值填充缺失值。
对于分类数据,也有类似的处理方法,可计算出最常见的类别用于填充,也可构建自定义填充器处理分类数据的填充。
编码分类变量
任何机器学习算法,无论是线性回归还是利用欧几里得距离的KNN算法,需要的输入特征都必须是数值。将分类数据转换为数值数据有以下几种方法。
方法1:定类等级的编码
定类等级的编码主要方法是将分类数据转换为虚拟变量 (dummy variable),用Pandas自动找到分类变量并进行编码; 或者创建自定义虚拟变量编码器,在流水线中工作。
虚拟变量的取值是1或0,代表某个类别的有无,代替定性数据。
方法2:定序等级的编码
在定序等级,由于数据的顺序有含义,使用虚拟变量是没有意义的,为了保持顺序,我们使用标签编码器。 标签编码器是指,顺序数据的每个标签都会有一个相关数值。
有时,如果数值数据是连续的,那么将其转换为分类变量可能是有意义的。Pandas有一个有用的函数叫作cut,可以将数据分箱(binning),亦称为分桶(bucketing),意思就是它会创建数据的范围。
特征缩放/归一化
特征缩放旨在改变特征的尺度,提高机器学习模型的准确率,也称为归一化。
常见的特征缩放操作有z分数标准化、min-max标准化和行归一化等。
4. 特征构建——生成新特征
使用现有特征构建全新的特征,以便理解特征交互情况。
构建新特征方法
方法1:最简单的方法是用Pandas将现有的特征扩大几倍;
用Pandas创建DataFrame,这也是Pandas的主要数据结构。这样做的优点是可以用很多属性和方法操作数据,从而对数据进行符合逻辑的操作,以深入了解我们使用的数据,以及如何最好地构建机器学习模型。
方法2:依靠数学的方法,使用scikit-learn包 ,扩展数值特征;
在处理数值数据、创建更多特征时,一个关键方法是使用 scikit-learn 的PolynomialFeatures 类。这个构造函数会创建新的列,它们是原有列的乘积,用于捕获特征交互。 更具体地说,这个类会生成一个新的特征矩阵,里面是原始数据各个特征的多项式组合,阶数小于或等于指定的阶数。
两个特征的乘积可以组成一对简单的交互特征,这种相乘关系可以用逻辑操作符AND来类比,它可以表示出由一对条件形成的结果:“该购买行为来自于邮政编码为98121的地区”AND“用户年龄在18~35岁之间”。这种特征在基于决策树的模型中及其常见,在广义线性模型中也经常使用。
方法3:编写自己的类。
针对文本的特征构建方法
在日常生活中,我们很大程度通过书面文本的方式进行沟通,通过建模,我们可以从中获得海量信息,如商户点评等。
这个工作又叫做自然语言处理(NLP,natural language processing)。
文本数据称为语料库(corpus),尤其是指文本内容或文档的集合。
文本数据比单个类别的文本复杂得多,因为长文本包括一系列类别,又称为词项(token)。
针对文本的特征构建有词袋法、TF-IDF向量化器等方法。
方法1:词袋法
将语料库转换为数值表示(也就是向量化)的常见方法是词袋(bag of words)。
词袋法基本思想:通过单词的出现来描述文档,完全忽略单词在文档中的位置。在它最简单的形式中,用一个袋子表示文本,不考虑语法和词序,并将这个袋子视作一个集合,其中重复度高的单词更重要。
词袋法分3个步骤:
- 分词(tokenizing):分词过程是用空白和标点将单词分开,将其变为词项。每个可能出现的词项都有一个整数ID。
- 计数(counting):简单地计算文档中词项的出现次数。
- 归一化(normalizing):将词项在大多数文档中的重要性按逆序排列。
方法2:TF-IDF向量化器
TF-IDF是一个用于信息检索和聚类的词加权方法。对于语料库中的文档,TF-IDF会给出其中单词的权重,表示重要性。
TF-IDF向量化器由两部分组成:
- TF(term frequency,词频):衡量词在文档中出现的频率。由于文档的长度不同,词在长文中的出现次数有可能比在短文中出现的次数多得多。因此,一般会对词频进行归一化,用其除以文档长度或文档的总词数。
- IDF(inverse document frequency,逆文档频率):衡量词的重要性。在计算词频时,我们认为所有的词都同等重要。但是某些词有可能出现很多次,但这些词并不重要。因此,我们需要减少常见词的权重,加大稀有词的权重。
5. 特征选择——发掘数据的新特征
在选择阶段,用所有原始和新构建的列(通常是单变量)进行统计测试,选取性能最佳的特征,以消除噪声影响,加速计算。
特征选择是从原始数据中选择对于预测流水线而言最好的特征的过程。即,给定n个特征,我们搜索其中包括k(k<n)个特征的子集来改善机器学习流水线的性能。
粗略地说,特征选择技术可以分为以下三类:
过滤:
过滤技术对特征进行预处理,以除去那些不太可能对模型有用处的特征。例如,我们可以计算出每个特征与响应变量之间的相关性或互信息,然后过滤掉那些在某个阈值之下的特征。过滤技术的成本比下面描述的打包技术低廉得多,但它们没有考虑我们要使用的模型,因此,它们有可能无法为模型选择出正确的特征。使用预过滤技术时需要谨慎,防止不经意地删除有用特征。
打包方法:
这些技术的成本非常高昂,但是可以试验特征的各个子集,这意味着我们不会意外地删除那些本身不提供什么信息但和其他特征组合起来却非常有用的特征。打包方法将模型视为一个能对推荐的特征子集给出合理评分的黑盒子。它们使用另外一种方法迭代地对特征子集进行优化。
嵌入式方法:
嵌入式方法将特征选择整合为模型训练过程的一部分,它不如打包方法强大,但成本也远不如打包方法那么高。与过滤技术相比,嵌入式方法可以选择出特别适合某种模型的特征。从这个意义上说,嵌入式方法在计算成本和结果质量之间实现了某种平衡。
选用正确的特征选择方法,一般建议:
如果特征是分类的,那么从SelectKBest开始,用卡方或基于树的选择器。
如果特征基本是定量的,一般用线性模型和基于相关性的选择器效果更好。
如果二元分类问题,考虑使用SelectFromModel和SVC,因为SVC会查找优化二元分类任务的系数。
在手动选择前,探索性分析会很有益处,不能低估领域知识的重要性。
以上就是经典特征工程的5个主要步骤,接下来简单介绍一下转换数据的方法。
特征转换——数学显神通
特征转换是一组矩阵算法,会在结构上改变数据,产生本质上全新的数据矩阵。
特征转换方法可以用每个列中的特征创建超级列(super-column),所以不需要创建很多新特征就可以捕获所有潜在的特征交互。因为特征转换算法涉及矩阵和线性代数,所以不会创造出比原有列更多的列,而且仍能提取出原始列中的结构。
与特征选择不同的是,特征选择仅限于从原始列中选择特征;特征转换算法则将原始列组合起来,从而创建可以更好地描述数据的特征。
主成分分析
主成分分析(PCA,principal components analysis)是将有多个相关特征的数据集投影到相关特征较少的坐标系上。这些新的、不相关的特征(超级列)叫主成分。主成分能替代原始特征空间的坐标系,需要的特征少,捕捉的变化多。
换句话说,PCA的目标是识别数据集中的模式和潜在结构,以创建新的特征,而非使用原始特征。和特征选择类似,如果原始数据是n×d大小(n是观察值数,d是原始的特征数),那么我们会将这个数据集投影到n×k(k<d)的矩阵上。
一般,PCA分为4个步骤:
创建数据集的协方差矩阵;
计算协方差矩阵的特征值;
降序排列特征值,保留前k个特征值;
用保留的特征向量转换新的数据点。
线性判别分析
线性判别分析(LDA,liear discriminant analysis)是特征变换算法,一般用作分类流水线的预处理步骤。和PCA一样,LDA的目标是提取一个新的坐标系,将原始数据集投影到一个低维空间中。
LDA和PCA的主要区别在于,LDA不会专注于数据的方差,而是优化低维空间,已获得最佳的类别可分性。
LDA分为5个步骤:
计算每个类别的均值向量;
计算类内和类间的散布矩阵;
计算 特征值和特征向量;
降序排列特征值,保留前k个特征向量;
使用前几个特征向量将数据投影到新空间。
三、案例:面部识别
这个案例研究的是scikit-learn中Wild数据集里的面部数据集。这个数据集叫作JAFFE,包括一些面部照片以及适当的表情标签。我们的任务是面部识别,即进行有监督的机器学习,预测图像中人物的表情。
1. 数据
首先加载数据集,导入用于绘制数据的包。在Jupyter Notebook的最上方尽量放置所有导入语句。
# 特征提取模块from sklearn.decomposition import PCAfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis# 特征缩放模块from sklearn.preprocessing import StandardScaler# 标准Python模块from time import timeimport numpy as npimport matplotlib.pyplot as plt# scikit-learn 的特征选择模块from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score#指标from sklearn.metrics import classification_report, confusion_matrix, accuracy_score# 机器学习模块from sklearn.linear_model import LogisticRegressionfrom sklearn.pipeline import Pipeline然后可以开始了!步骤如下所示。
(1) 首先加载数据集:
import osdata_path='F:\python\locust\.idea\dictionaries\jaffe'data_dir_list=os.listdir(data_path)img_rows=256img_cols=256num_channel=1num_epoch=10img_data_list=[]import cv2for dataset in data_dir_list: img_list=os.listdir(data_path+'/'+dataset) print('Loaded the images of dataset-'+'{}\n'.format(dataset)) for img in img_list: input_img=cv2.imread(data_path+'/'+dataset+'/'+img) input_img=cv2.cvtColor(input_img,cv2.COLOR_BGR2GRAY) input_img_resize=cv2.resize(input_img,(128,128)) img_data_list.append(input_img_resize)img_data=np.array(img_data_list)img_data=img_data.astype('float32')img_data=img_data/255img_data.s(2) 检查图像数组,输出图像大小:
n_samples,h,w=img_data.shapen_samples,h,w(213,128,128)
一共有213个样本(图像),高度和宽度都是128像素。
(3) 接着设置流水线的x和y变量:
#直接使用 不管相对像素位置X=img_datalabels = ['angry','disgust','fear','happy','','','']Y=labelsn_features=X.shape[1]n_features
16384
n_features的数量是16384,因为:
128*128=16384
输出数据的形状
X.shape
(213,16384)
2. 数据探索
数据有213行和16384列。我们可以绘制一幅图像,进行探索性数据分析。
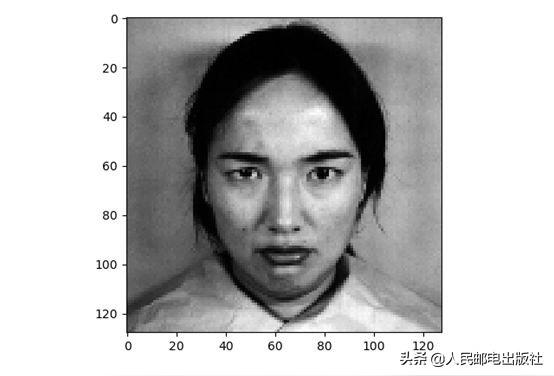
#绘制其中一张脸
plt.imshow(X[6].reshape((h,w)), cmap=plt.cm.gray)print(Y[0])plt.show()给出的标签是:
'angry'
该图像如下所示。
我们在缩放后重新绘制一次图像:
#缩放后重新绘制一次图像print(X.shape)img = StandardScaler().fit_transform(X[6]).reshape((h,w))plt.imshow(img)plt.show()print(Y[0])输出:
'angry'
得到的图像如下所示。
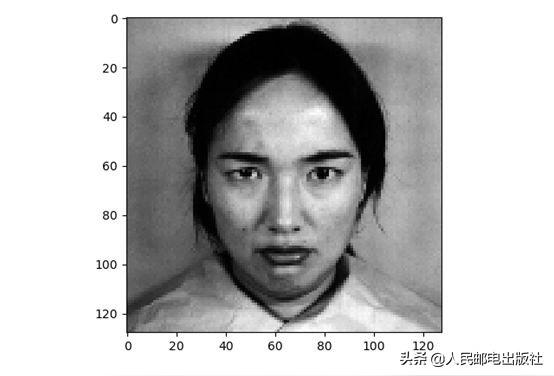
可以看见,图像略有不同,脸部周围的像素变暗了。现在设置预测的标签:
#预测表情
target_names=labels_textn_samples=X.shape[0]n_classes=len(names)print("Total dataset size:")print("n_samples: %d" % n_samples)print("n_features: %d" % n_features)print("n_classes: %d" % n_classes)输出是:
Total dataset size:n_samples: 213n_features: 16384n_classes:73. 应用面部识别
现在可以开始构建机器学习流水线来创建面部识别模型了。
(1) 首先创建训练集和测试集,对数据进行分割:
# 把数据分成训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25,random_state=1)(2) 现在可以在数据集上进行主成分分析(PCA)了:
先将PCA 实例化,在进入流水线之前进行数据扩充。方法如下:
# PCA 实例化pca = PCA(n_components=50, whiten=True)# 创建流水线,扩充数据,然后应用PCApreprocessing = Pipeline([('scale', StandardScaler()), ('pca', pca)])(3) 现在拟合流水线:
print("Extracting the top %d eigenfaces from %d faces" % (50, X_train.shape[0]))# 在训练集上拟合流水线preprocessing.fit(X_train)# 从流水线上取PCAextracted_pca = preprocessing.steps[1][1](4) print 语句的输出是:
Extracting the top 50 eigenfaces from 159 faces(5) 看一下碎石图:
# 碎石图plt.plot(np.cumsum(extracted_pca.explained_variance_ratio_))得到的图像如下图所示。
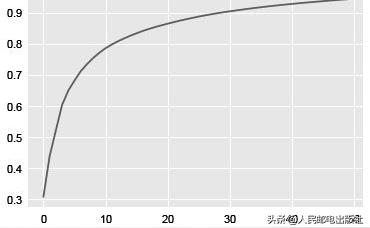
可以看出,30 个主成分就可以表示90%以上的方差,和原始的特征数量相比很可观。
(6) 可以创建函数,绘制PCA 的主成分:
comp = extracted_pca.components_image_shape = (h, w)def plot_gallery(title, images, n_col, n_row):plt.figure(figsize=(2. * n_col, 2.26 * n_row))plt.suptitle(title, size=16)for i, comp in enumerate(images):plt.subplot(n_row, n_col, i + 1)vmax = max(comp.max(), -comp.min())plt.imshow(comp.reshape(image_shape), cmap=plt.cm.gray,vmin=-vmax, vmax=vmax)plt.xticks(())plt.yticks(())plt.subplots_adjust(0.01, 0.05, 0.99, 0.93, 0.04, 0.)plt.show()(7) 现在可以调用plot_gallery 函数:
plot_gallery('PCA componenets', comp[:16], 4,4)输出如下图所示。

可以看见每行每列的PCA 主成分了!这些特征脸(eigenface)是PCA 模块发现的人脸特征。
每个主成分都包括了可以区分不同人脸的重要信息,例如:
第四行第一列的特征脸好像突出了腮部表情;
第二行第三列的特征脸好像显示了嘴部的变化。
当然,不同的面部数据集会输出不同的特征脸。接下来创建的函数可以更清晰地显示混淆矩阵,包括热标签和归一化选项:
import itertoolsdef plot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('True label')plt.xlabel('Predicted label')现在不使用PCA 也可以看见差异。我们查看一下模型的准确率:
# 不用PCA,看看差异t0 = time()logreg = LogisticRegression()param_grid = {'C': [1e-2, 1e-1, 1e0, 1e1, 1e2]}clf = GridSearchCV(logreg, param_grid)clf = clf.fit(X_train, y_train)best_clf = clf.best_estimator_# 用测试集进行预测y_pred = best_clf.predict(X_test)print(accuracy_score(y_pred, y_test), "Accuracy score for best estimator")print(plot_confusion_matrix(confusion_matrix(y_test, y_pred,labels=range(n_classes)), target_names))print(round((time() - t0), 1), "seconds to grid search and predict the test set")输出如下:
0.7592592592592593 Accuracy score for best estimator309.5 seconds to grid search and predict the test set在只使用原始像素的情况下,我们的线性模型可以达到75.9%的准确率。下面看看应用PCA
后会不会有所不同,把主成分数量设置成200:
# 用PCAt0 = time()face_pipeline = Pipeline(steps=[('PCA', PCA(n_components=200)), ('logistic',logreg)])pipe_param_grid = {'logistic__C': [1e-2, 1e-1, 1e0, 1e1, 1e2]}clf = GridSearchCV(face_pipeline, pipe_param_grid)clf = clf.fit(X_train, y_train)best_clf = clf.best_estimator_# 用测试集进行预测y_pred = best_clf.predict(X_test)print(accuracy_score(y_pred, y_test), "Accuracy score for best estimator")print(classification_report(y_test, y_pred, target_names=target_names))print(plot_confusion_matrix(confusion_matrix(y_test, y_pred,labels=range(n_classes)), target_names))print(round((time() - t0), 1), "seconds to grid search and predict the test set")应用PCA 后的输出如下:
0.6666666666666666 Accuracy score for best estimator4.9 seconds to grid search and predict the test set有意思!可以看到,准确率下降到了66.7%。
现在做一个网格搜索,寻找最佳模型和准确率。首先创建一个执行网格搜索的函数,它会输
出准确率、参数、平均拟合时间和平均分类时间。函数的创建方法如下:
def get_best_model_and_accuracy(model, params, X, y):grid = GridSearchCV(model, # 网格搜索的模型params, # 搜索的参数error_score=0.) # 如果出错,正确率是0grid.fit(X, y) # 拟合模型和参数# 经典的性能参数print("Best Accuracy: {}".format(grid.best_score_))# 得到最佳准确率的最佳参数print("Best Parameters: {}".format(grid.best_params_))# 拟合的平均时间(秒)print("Average Time to Fit (s):{}".format(round(grid.cv_results_['mean_fit_time'].mean(), 3)))# 预测的平均时间(秒)# 从该指标可以看出模型在真实世界的性能print("Average Time to Score (s):{}".format(round(grid.cv_results_['mean_score_time'].mean(), 3)))现在可以创建一个更大的网格搜索流水线,包含更多的组件:
缩放模块;
PCA 模块,提取捕获方差的最佳特征;
线性判别分析(LDA)模块,创建区分人脸效果最好的特征;
线性分类器,利用上述3 个特征工程模块的结果,尝试对人脸进行区分。
创建大型流水线的代码如下:
# 网格搜索的大型流水线face_params = {'logistic__C':[1e-2, 1e-1, 1e0, 1e1, 1e2],'preprocessing__pca__n_components':[100, 150, 200, 250, 300],'preprocessing__pca__whiten':[True, False],'preprocessing__lda__n_components':range(1, 7)# [1, 2, 3, 4, 5, 6] recall the max allowed is n_classes-1}pca = PCA()lda = LinearDiscriminantAnalysis()preprocessing = Pipeline([('scale', StandardScaler()), ('pca', pca), ('lda', lda)])logreg = LogisticRegression()face_pipeline = Pipeline(steps=[('preprocessing', preprocessing), ('logistic',logreg)])get_best_model_and_accuracy(face_pipeline, face_params, X, y)结果如下:
Best Accuracy: 0.8276995305164319Best Parameters: {'logistic__C': 10.0, 'preprocessing__lda__n_components': 6,'preprocessing__pca__n_components': 100, 'preprocessing__pca__whiten': True}Average Time to Fit (s): 0.213Average Time to Score (s): 0.007可以看见,准确率大幅度提高,预测的速度极快!
有很多方法可以增强机器学习的效果,通常我们认为最主要的两个特征是准确率和预测/拟合时间。如果利用特征工程工具后,机器学习的流水线的准确率在交叉验证中有所提高,或者拟合/预测的速度加快,那就代表特征工程成功了。
当然如果既优化准确率又优化时间,构建出更好的流水线那就更好了。
以上内容整理自《特征工程入门与实践》一书,作者:Sinan Ozdemir[土],Divya Susarla[土]。

[土] Sinan Ozdemir [土]Divya Susarla 著 庄嘉盛 译
本书带你从零入手,全面了解特征工程,从而提升机器学习算法的效率和准确率。学习本书:
你会了解特征工程的完整过程,使机器学习更加系统、高效。
你会从理解数据开始学习,机器学习模型的成功正是取决于如何利用不同类型的特征,例如连续特征、分类特征等。
你将了解何时纳入一项特征、何时忽略一项特征以及其中的原因。
你还会学习如何将问题陈述转换为有用的新特征,如何提供由商业需求和数学见解驱动的特征,以及如何在自己的机器上进行机器学习,从而自动学习数据中的特征。
最重要的是,本书在讲解的同时会增加很多实例,帮助理解。
相关阅读:《精通特征工程》,作者:Alice Zheng[美],Amanda Casari[美]。

[美]Alice Zheng [美]Amanda Casari 著 陈光欣 译
本书介绍了大量的特征工程技术,阐明特征工程的基本原则。主要内容包括:机器学习流程中的基本概念,数值型数据的基础特征工程,自然文本的特征工程,词频-逆文档频率,高效的分类变量编码技术,主成分分析,模型堆叠,图像处理等。